I had an unsettling experience a few days back where I was booping along, writing some code, asking ChatGPT 4.0 some questions, when I got the follow message: “You’ve reached the current usage cap for GPT-4, please try again after 4:15 pm.” I clicked on the “Learn More” link and basically got a message saying “we actually can’t afford to give you unlimited access to ChatGPT 4.0 at the price you are paying for your membership ($20/mo), would you like to pay more???”
It dawned on me that OpenAI is trying to speedrun enshitification. The classic enshitification model is as follows: 1) hook users on your product to the point that it is a utility they cannot live without, 2) slowly choke off features and raise prices because they are captured, 3) profit. I say it’s a speedrun because OpenAI hasn’t quite accomplished (1) and (2). I am not hooked on its product, and it is not slowly choking off features and raising prices– rather, it appears set to do that right away.
While I like having a coding assistant, I do not want to depend on an outside service charging a subscription to provide me with one, so I immediately cancelled my subscription. Bye, bitch.
But then I got to thinking: people are running LLMs locally now. Why not try that? So I procured an Nvidia RTX 3060 with 12gb of VRAM (from what I understand, the entry-level hardware you need to run AI-type stuff) and plopped it into my Ubuntu machine running on a Ryzen 5 5600 and 48gb of RAM. I figured from poking around on Reddit that running an LLM locally was doable but eccentric and would take some fiddling.
Reader, it did not.
I installed Ollama and had codellama running locally within minutes.
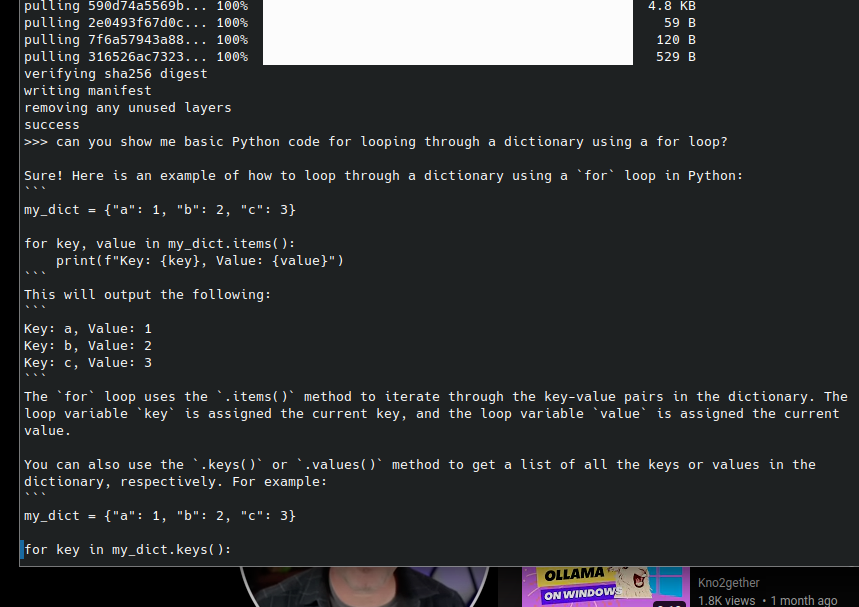
It was honestly a little shocking. It was very fast, and with Ollama, I was able to try out a number of different models. There are a few clear downsides. First, I don’t think these “quantized” (I think??) local models are as good as ChatGPT 3.5, which makes sense because they are quite a bit smaller and running on weaker hardware. There have been a couple of moments where the model just obviously misunderstands my query.
But codellama gave me a pretty useful critique of this section of code:
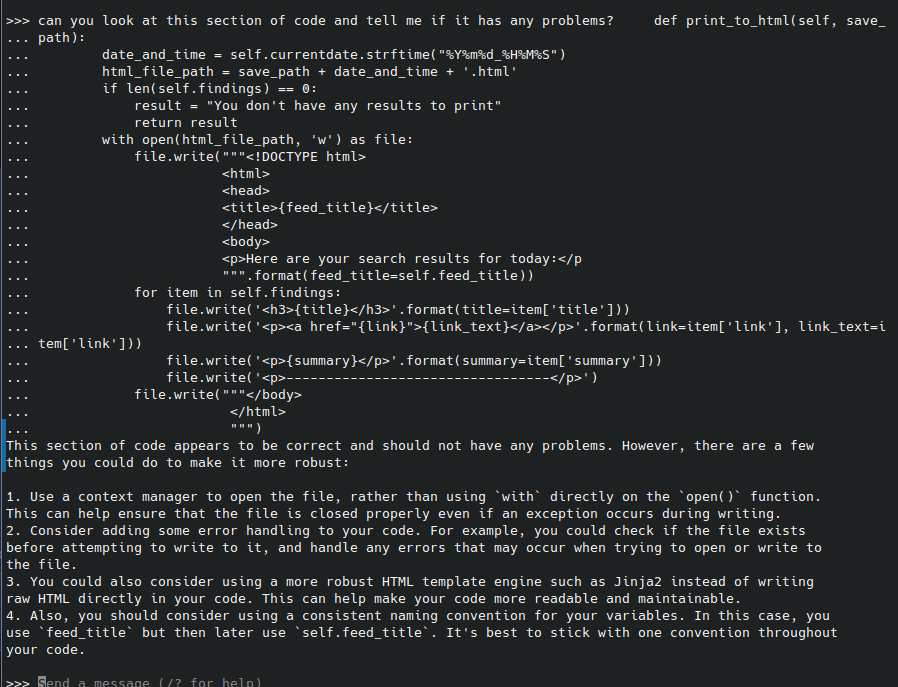
… which is really what I need from a coding assistant at this point. I later asked it to add some basic error handling for my “with” statement and it did a good job. I will also be doing more research on context managers to see how I can add one.
Another downside is that the console is not a great UI, so I’m hoping I can find a solution for that. The open-source, locally-run LLM scene is heaving with activity right now, and I’ve seen a number of people indicate they are working on a GUI for Ollama, so I’m sure we’ll have one soon.
Anyway, this experience has taught me that an important thing to watch now is that anyone can run an LLM locally on a newer Mac or by spending a few hundred bucks on a GPU. While OpenAI and Google brawl over the future of AI, in the present, you can use Llama 2.0 or Mistral now, tuned in any number of ways, to do basically anything you want. Coding assistant? Short story generator? Fake therapist? AI girlfriend? Malware? Revenge porn??? The activity around open-source LLMs is chaotic and fascinating and I think it will be the main AI story of 2024. As more and more normies get access to this technology with guardrails removed, things are going to get spicy.
Leave a Reply