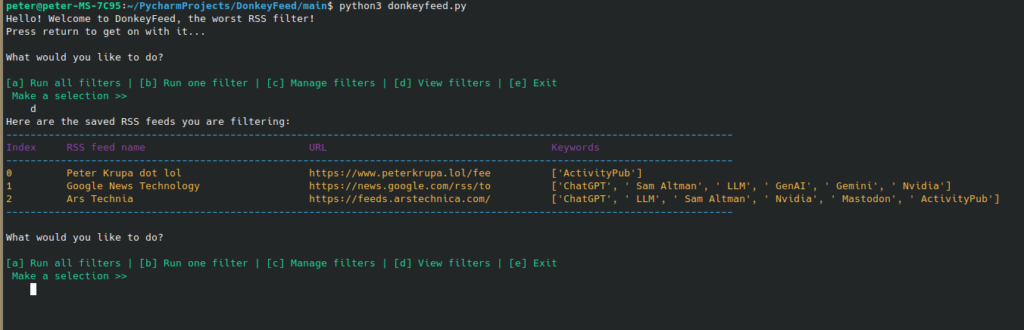
I just finished my first Python app, so of course now I have to re-write it. The app is called DonkeyFeed, it’s a simple little dingus that is supposed to filter RSS feeds for certain keywords: Users save a list of RSS feed links with their associated keywords, then run the searches anytime and save any results in an easy-to-read HTML file.
But now I’m realizing I designed the user interface as rigid if-then flowchart of options, when what I really should be doing is an input() loop where users can enter commands with arguments to run, add, remove, or modify filters right from the cursor, instead of poking around with menu options.
Fortunately, I focused this project on using a class-based structure, with all the moving parts put into separate objects. There’s a class for handling the .JSON file with the RSS roster, a class for parsing the RSS feeds, a class for handling configurations, a class for the user menus, etc., all with their various associated methods. So changing the UI won’t mean untangling a bunch of stuff, more like reassembling existing parts into different loops and logic.
In general, I’m starting to feel like that’s what most of coding is: take a thing and plug it into, get it to talk to, or wrap it in another thing. You build your code as a series of things that can be made to work with other things, then take it home, throw it in a pot, add some broth, a potato… baby you got a stew going! Eh, I digress.
I had a fun time yesterday playing with customized prompts in Ollama. These basically wrap the prompts you give to your local LLM with a standing prompt that conditions all responses. So, if you want your LLM to respond to queries briefly, you can specify that. Or of you want it to respond to every prompt like Foghorn Leghorn, hey. You can also adjust the “temperature” of the model: The spicier you make it, the weirder things get.
First I tried to make a conspiracy theorist LLM, and it didn’t really work. I used llama2-uncensored and it was relentlessly boring. It kind of “both sides”ed everything and was studiously cautious about taking a position on anything. (Part of the problem may have been that I had the temperature set at 0.8 because I thought the scale was 0-1.)
So I moved on to a different uncensored model, dolphin-mixtral, and oh boy. This time, I set the temperature to 2 and we were off to the races:
OK buddy, go home, you’re drunk.
Then I cranked the temperature up to 3 and made a mean one…
… and a kind of horny/rapey one that I won’t post here. It was actually very easy, in a couple of minutes, to customize an open-source LLM to respond however you want. I could have made a racist one. I could have made one that endlessly argues about politics. I could have made one that raises concerns about Nazis infiltrating the Ukrainian armed forces, or Joe Biden’s age, or the national debt.
Basically, there’s a lot of easy ways to customize an LLM to make everyone’s day worse, but I don’t think I could have customized one to make anything better. There’s an asymmetry built into the technology. A bot that says nice things isn’t going to have the same impact as a bot that says mean things, or wrong things.
It got me thinking about Brandolini’s law, the asymmetry of bullshit, “The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it,” which you can generalize even further to “it’s easier to break things than to make things.”
As the technology stands right now, uncensored open-source LLMs can be very good at breaking things– trust, self-worth, fact-based reality, sense of safety. It would be trivial to inject LLM-augmented bots into social spaces and corrupt them with hate, conflict, racism, and disinformation. It’s a much bigger lift to use an LLM to make something.
The cliche is that a technology is only as good as its user, but I’m having a hard time imaging a good LLM user who can do as much good as a bad LLM user can do bad.
Does it ever happen where you have some plans for a day, but your son is like “I wonder if you could code Blackjack in Python” and you can’t get it out of your head, so you open up your IDE and start tapping away, and you’re breaking down the problem and sorting out the structure and putting different parts of the game into different objects and then you’re basically done, but it doesn’t work for some reason, so then you troubleshoot that, and then it doesn’t work for a different reason, so you troubleshoot that, and then you call your son over and say “hey, check it out!” and then he checks it out and it doesn’t work again for a new and unforeseen reason, and you’re kinda mad at this thing but also you can’t put it down even for a second even though your dog needs to go out and someone should do the dishes and you had plans for today, but you’ve got this burr under your saddle that you can’t get rid of so you smash one bug after another until finally you hit “execute” and you play a game of Blackjack, and then another one, and then another one, and everything works as expected, and it kinda feels like you wasted the whole morning banging your head against this thing, but in the end, you coded Blackjack in Python and it works, so that’s not nothing.
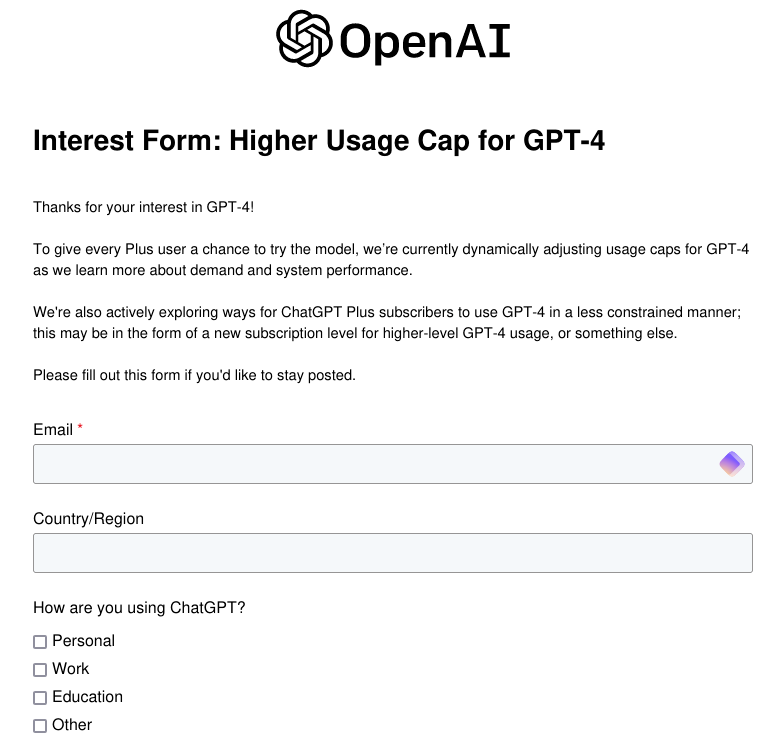
I had an unsettling experience a few days back where I was booping along, writing some code, asking ChatGPT 4.0 some questions, when I got the follow message: “You’ve reached the current usage cap for GPT-4, please try again after 4:15 pm.” I clicked on the “Learn More” link and basically got a message saying “we actually can’t afford to give you unlimited access to ChatGPT 4.0 at the price you are paying for your membership ($20/mo), would you like to pay more???”
It dawned on me that OpenAI is trying to speedrun enshitification. The classic enshitification model is as follows: 1) hook users on your product to the point that it is a utility they cannot live without, 2) slowly choke off features and raise prices because they are captured, 3) profit. I say it’s a speedrun because OpenAI hasn’t quite accomplished (1) and (2). I am not hooked on its product, and it is not slowly choking off features and raising prices– rather, it appears set to do that right away.
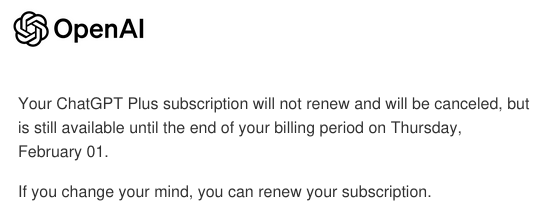
While I like having a coding assistant, I do not want to depend on an outside service charging a subscription to provide me with one, so I immediately cancelled my subscription. Bye, bitch.
But then I got to thinking: people are running LLMs locally now. Why not try that? So I procured an Nvidia RTX 3060 with 12gb of VRAM (from what I understand, the entry-level hardware you need to run AI-type stuff) and plopped it into my Ubuntu machine running on a Ryzen 5 5600 and 48gb of RAM. I figured from poking around on Reddit that running an LLM locally was doable but eccentric and would take some fiddling.
Reader, it did not.
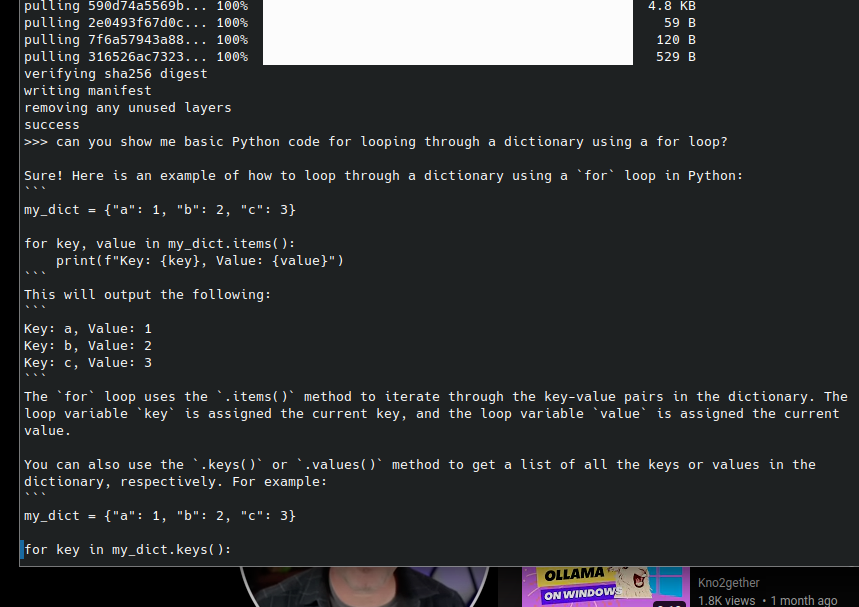
I installed Ollama and had codellama running locally within minutes.
It was honestly a little shocking. It was very fast, and with Ollama, I was able to try out a number of different models. There are a few clear downsides. First, I don’t think these “quantized” (I think??) local models are as good as ChatGPT 3.5, which makes sense because they are quite a bit smaller and running on weaker hardware. There have been a couple of moments where the model just obviously misunderstands my query.
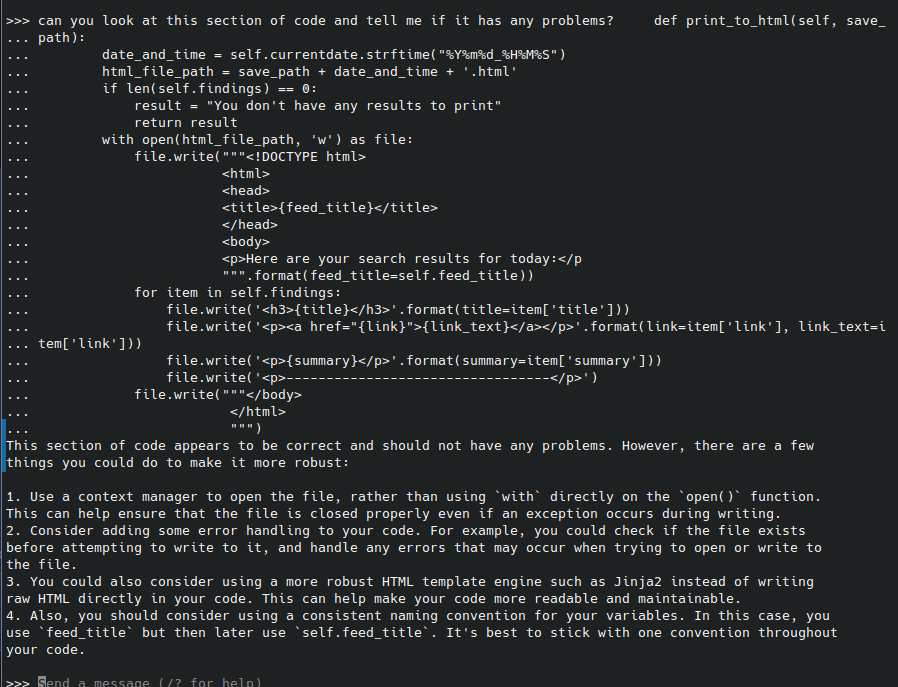
But codellama gave me a pretty useful critique of this section of code:
… which is really what I need from a coding assistant at this point. I later asked it to add some basic error handling for my “with” statement and it did a good job. I will also be doing more research on context managers to see how I can add one.
Another downside is that the console is not a great UI, so I’m hoping I can find a solution for that. The open-source, locally-run LLM scene is heaving with activity right now, and I’ve seen a number of people indicate they are working on a GUI for Ollama, so I’m sure we’ll have one soon.
Anyway, this experience has taught me that an important thing to watch now is that anyone can run an LLM locally on a newer Mac or by spending a few hundred bucks on a GPU. While OpenAI and Google brawl over the future of AI, in the present, you can use Llama 2.0 or Mistral now, tuned in any number of ways, to do basically anything you want. Coding assistant? Short story generator? Fake therapist? AI girlfriend? Malware? Revenge porn??? The activity around open-source LLMs is chaotic and fascinating and I think it will be the main AI story of 2024. As more and more normies get access to this technology with guardrails removed, things are going to get spicy.
I’m working on coding a desktop RSS reader with a GUI and the process is going like this: (1) design a feature, (2) work on the feature on one end, (3) find out it doesn’t work or I need to learn some new library to make it work on the other end, (4) mostly finish the feature but now I have to completely change the other end, (5) also, I’ve thought about it more and changed the parameters for the features I want, so (6) start over at (1).
It’s frustrating, but I realized I’m not just learning coding with this process, I’m learning design and project management, and even though I am the client, the designer, the developer, and the project manager, I’m still having communication issues haha lol lmao. OK, but I have been learning-by-doing and some of the early lessons are as follows:1
Define the features you want from the beginning. I imagine this is kind of a moving target in many cases depending on the client, but as much as possible, I should nail down the stuff that is nail-down-able.
Do the back end first. Break the work down into as many pieces (classes/methods) as possible that return discrete objects that can be manipulated and used in whatever way the front-end designer (future me) decides.
GUIs suck, use a browser if you need to display a lot of content. Tkinter has been really interesting and I’ve enjoyed the learning process, but using it to display articles for reading is a terrible idea. The GUI should be used for interacting with the functions in my program and getting user input, and that’s it.
Attending to the first bullet point on my little list here, and in response to some comments from a friend, I’m going to pivot (!!) away from a desktop RSS feed reader and toward a desktop RSS feed parser that searches for keywords and saves the entries that hit into an HTML document that can be opened in a browser for review. This means I can focus on building the logic of the parser, plus a mechanism for managing a database of saved RSS feeds and search terms. That’s probably a lot for now, so I’ll leave the front-end GUI for later, when I have everything running correctly from the terminal. OK? OK.
Do not @ me about agile. I am familiar with agile. I have thoughts about it, but I will not put them here, yet. ↩︎
When I started this little blog, I wondered how anyone would find it. In the old days, you would do SEO so your posts show up in search. That involved writing little summaries of each post, making the links attractive to Google’s crawlers, posting a sitemap, linking to other blogs and soliciting linkbacks. Then later on, with Web 2.0, you would market your sites by building a “brand” on social media: setting up a Facebook page, boosting on Twitter, starting fights in the comments of YouTube videos, etc.
But Google search is now a hot mess, and LLM-generated content is about to make it even more useless than it is now, so I’m not even trying to play that game. And building a brand on algorithmic social media seems like a suicide mission. I figured it was more important to do the thing and then worry about finding readers later.
But I did stick it into the fediverse by activating an ActivityPub plugin, and the results have been surprising! I’ve consistently been getting thoughtful comments and boosts on every post, and the blog already has a couple dozen followers on Mastodon.
Huge caveat: I’m writing about very Mastodon-adjacent topics, like coding and LLMs. And at the moment, with only a couple million users on the fediverse, reach is certainly limited. But I’m starting to believe the ActivityPub protocol does indeed have the potential to restructure how people who write and read find each other on the open web, without any algorithmic intermediaries harvesting our attention for profit and fucking with us.
Today I reached the limits of ChatGPT 4.0’s usefulness for coding, and I think it’s a pretty bad sign for the potential of LLMs as a transformative technology. Up to this point, it’s been useful as a sort of very fancy spell check. If I need a quick refresher on basic syntax in Python, or if a section of code is not working due to a rookie error, ChatGPT is a nice way to get things unstuck as fast as possible. I don’t want to have to pull a physical dictionary off a shelf to look up how to spell “reservoir” every time I write it, and I don’t want to plumb the depths of Stack Overflow every time I want a refresher on how class inheritance works.
The problem is that when things get to an intermediate level of complicated, ChatGPT can start giving you VERY confident-sounding answers that are completely wrong, or at least so dumb and backwards that you’re better off starting from scratch. It’s hard to put my finger on exactly when this starts. When it comes to coding, I’m not a domain expert (obviously, or I wouldn’t be asking ChatGPT), but sometimes over the course of a series of queries, I get a sort of a sense, a little tingle, a suspicion that the solutions offered seem way too loopy and repetitive to be any good.
For me today, this happened during a series of queries to help with building a GUI for my RSS reader using Tkinter. The details are tedious, but it boils down to ChatGPT offering me a solution that didn’t work, then offering me a different solution that didn’t work, then offering me the FIRST solution again, and that’s when I realized this thing isn’t actually thinking. OK, I knew that already, intellectually, but it can really sound like it is trouble shooting! LLMs specialize in convincing you that they aren’t just massive statistical engines pooping out the most plausible next token, but that’s really all they are.
For whatever reason, when it came to the Tkinter library, ChatGPT was incapable of explaining the basic structure, terrible at offering elegant structures to get started, and worse at debugging things when they ran into trouble. Part of me suspects this is because the output of Tkinter is graphic, and the model breaks down where the linguistic direction is supposed to translate into a visual result. So maybe that. But the other problem is that there is more than one way to do things in Tkinter. You can slave and place widgets in the UI in any number of ways depending on preference, but you need to take a consistent approach, and ChatGPT clearly wasn’t able to keep track of it over the course of trouble shooting.
This makes me very cautious about using ChatGPT in the future to compose complex sections of code employing tools I don’t fully understand yet. While it can be good for getting started, today’s experience taught me that I’m better off learning from other sources before I dive in, as I might just have to do it all over again anyway.
ChatGPT is still an excellent tool for basic coding support, but it is a support tool, one of many in an IDE. This is worth emphasizing because some LLM boosters would have you believe this technology is set to change life as we know it, replacing human workers and revolutionizing how we do literally everything. It’s just not. There’s no depth to it. It’s inconsistent, unreliable, and untrustworthy. And I’m pretty worried the powers that be are going to try to force it into every corner of our digital lives anyway.
I feel like I was just saying this the other day. People don’t write websites or blogs for human readers anymore: They write them for the machines.
The relentless optimizing of pages, words, paragraphs, photos, and hundreds of other variables has led to a wasteland of capital-C Content that is competing for increasingly dwindling Google Search real estate as generative AI rears its head. You’ve seen it before: the awkward subheadings and text that repeats the same phrases a dozen times, the articles that say nothing but which are sprayed with links that in turn direct you to other meaningless pages. Much of the information we find on the web — and much of what’s produced for the web in the first place — is designed to get Google’s attention.
It’s a very good article. LLMs are not new in this regard, their enshitifcation of the web is just finishing a process that is already 90% complete thanks to our reliance on ad-supported algorithmic search as a means of sorting information.
I don’t like the idea of a coding project that’s just you typing out what someone in a YouTube video tells you to type. That’s like doing a crossword puzzle with someone telling you what letters to put in each square. First, it’s boring. You don’t get the satisfaction of solving it on your own. Second, you can’t possibly learn much. There is no “right” way to code something, there are only better ways and worse ways, and part of learning is doing something in the stupidest way possible and then finding out first-hand why you shouldn’t do it that way.
Anyway, I’m coding this desktop RSS reader I’ll call DonkeyFeed, for no particular reason. The GitHub repository is here, and apologies in advance, I still have no fucking idea how Git works, so I hope I didn’t accidentally expose my ass. I selected a desktop RSS reader with a GUI as a project because I need one, and it seems like the kind of thing I can iterate gradually as I learn how the pieces work.
So far, that’s what is happening!
It is turning out to be a great project for working with a number of different libraries and moving parts. Using a GUI means working on a front end and user experience and learning Tkinter. For RSS parsing on the back end, I have to learn to use feedparser and figure out how to get the parts of the RSS feed that I need, put them into some kind of array, and put that array into an object to be placed in a window. Then I’ll also need to manage a database, add user-initiated functionality, put in some testing modules, and maybe even write a readme.txt, who knows.
So far, I have mostly worked on the GUI and the RSS parsing. For the former, I’m building a “Window” class with methods for all the different widgets (buttons, input fields, letterboxes, etc.), although I’m still not super clear on what the most extensible/useable way to do that will be. I’ve made more progress on the RSS parsing: I’m building a class that can be instantiated for a single RSS feed, with methods that return the separate parts of the feed so I can place them in the window how I want later.
I worked with ChatGPT quite a bit in building this part, everything from very basic debugging (I’m still occasionally forgetting parentheses lol) to back-and-forth about how some feature will work. I’m finding ChatGPT can be dangerous because it WILL GIVE YOU WHAT YOU ASK FOR. This is a known problem with LLMs, sycophancy bias. Basically, the LLM tells you want you want to hear. My coding skills are so incipient at the moment that for now, I’m mostly getting “actually”ed by ChatGPT. Like here. Ooof. Big L.
But as my queries get more sophisticated, it is happy to help me hang myself. For example, to parse an RSS feed, I built a method that uses feedparser to send the title, link, and summary of each entry to a list, and those items could then be retrieved for display. That is: three separate lists. Maybe you can see where this is going. ChatGPT was happy to assist me with this. It was later that I realized keeping three separate lists for items that need to be synched up with each other was… problematic. ChatGPT cheerfully agreed:
It’s a great reminder that coding assistants are ASSISTANTS. You have to catch this stuff, they will not stop you from showing your ass, on the contrary, they will 100% help you pull your pants down and then tell you “good job, sir!!” Indeed, note that I’m the one who suggested using a dictionary here instead. I may actually be showing my ass in a new and exciting way.
Anyway, the next thing I have to change in this code is to send the feed elements to a dictionary instead of three separate lists, and then I will be ready to test. I haven’t built any testing modules yet, but it’s on my mental list of things to do. Another functionality I need to add soon is some kind of database management, so a user can save a list of RSS feeds and query them whenever they open the program. Off to code.
As part of my “learn Python” project, I’m building a desktop RSS reader. This could be a pretty straight-forward little dingus, but I want to use it to explore structuring code in a way that can be extended and tested later, so I’m trying a class-based approach. It has been like a lot of the other creative things I’ve done over the years, in the sense that you work on it for a bit, create something bad, then smoosh it down and start over with what you’ve learned.
My big take-away so far is that (SHOCKING!!) ChatGPT is not as useful as it looks at first. OK, so it definitely IS useful. You can ask it things like “how would I build a basic GUI using Python?” and it gives you Tkinter syntax examples to get the ball rolling. But it reminds me of doing translation (my day job) using a machine translation engine: 1) you get something that looks good; 2) great! you set out to tweak it and clean it up; 3) you find out it needs a fundamental re-write; 4) you’ve Ship of Thesus’d the thing, and it took longer than just doing it from scratch.
Still, it’s been useful when I get stuck, and it’s a nice place to get quick answers to easy questions. What this experience is reinforcing for me is that humans are still best at the big-brained strategic/creative planning. While something like Code Pilot can help you build the pieces, you’re the one who has to know how to put the pieces together.